Amazon Textract(ドキュメントからテキストやデータを簡単に自動抽出)
表形式のテキストが抽出出来るらしいとのことで「これはアツいのでは」と思い、AWSのTextractを試してみる。
準備
公式ドキュメントを見ながら進めてみます。
Detecting Document Text with Amazon Textract - Amazon Textract
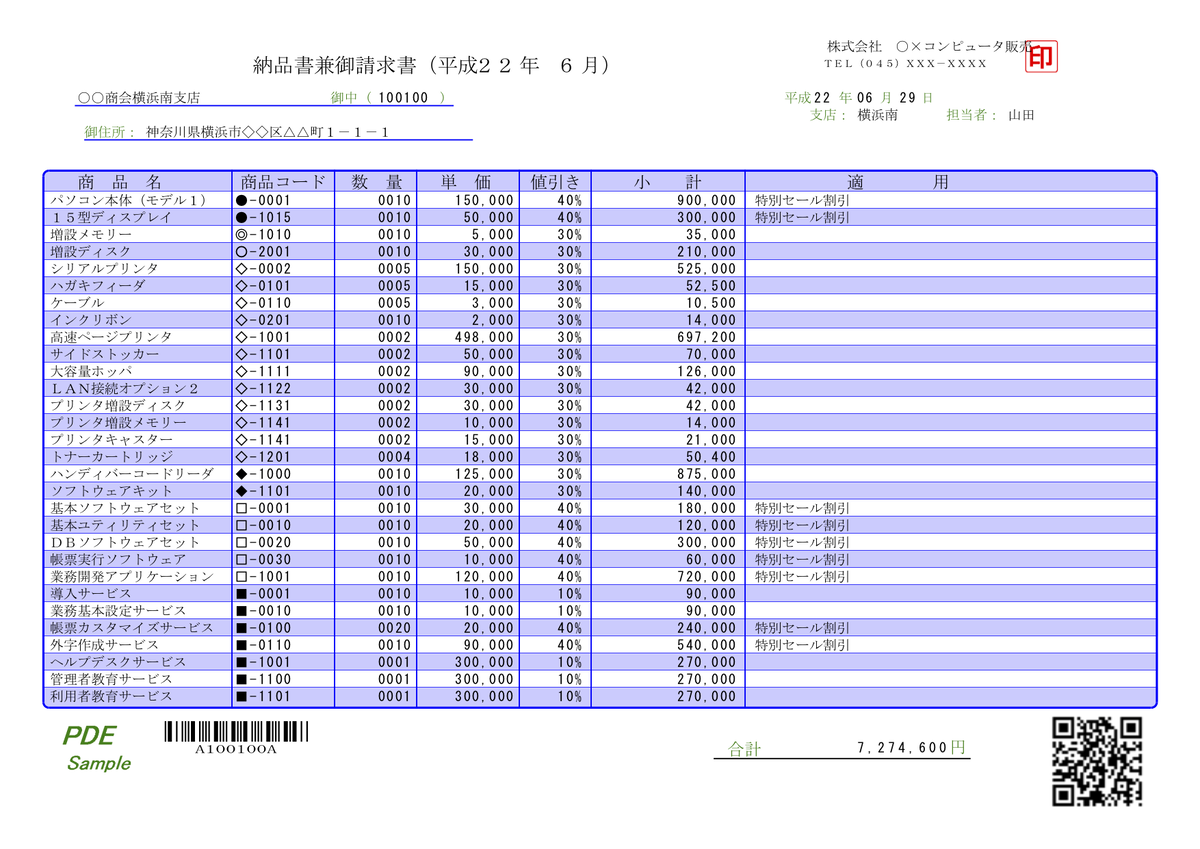
ドキュメントによるとS3にOCR対象のファイルをアップする必要があるらしい。下記から拝借した納品書みたいなやつをS3にアップする。
http://www.hitachi.co.jp/Prod/comp/soft1/pde/info/concept/pdf/sample1_b.pdf
aws-cliでOCR
aws-cliを使ってコマンドでtextractを呼び出してみます。
$ aws textract detect-document-text \
--document '{"S3Object":{"Bucket":"amazon-textract-sample","Name":"estimate.pdf"}}'
Could not connect to the endpoint URL: "https://textract.ap-northeast-1.amazonaws.com/"
そうか東京リージョンはtextract対応してないのか。リージョンを指定して実行します。
$ aws textract detect-document-text \
--region us-west-1 --document '{"S3Object":{"Bucket":"amazon-textract-sample","Name":"estimate.pdf"}}'
Could not connect to the endpoint URL: "https://textract.us-west-1.amazonaws.com/"
us-west-1も対応してないのかな。us-east-1にしてみる。お、別のエラーになったぞい。
$ aws textract detect-document-text \ ✘ 255
--region us-east-1 --document '{"S3Object":{"Bucket":"amazon-textract-sample","Name":"estimate.pdf"}}'
An error occurred (UnsupportedDocumentException) when calling the DetectDocumentText operation: Request has unsupported document format
どうやらpdfファイルは対応してないぽい。pngに変換してS3にアップし直す。
python - Unsupported Document format while using Amazon Textract, - Stack Overflow
再度コマンドを実行する。
$ aws textract detect-document-text --region us-east-1 --document '{"S3Object":{"Bucket":"amazon-textract-sample","Name":"estimate.png"}}'
{
"DocumentMetadata": {
"Pages": 1
},
"Blocks": [
{
"BlockType": "PAGE",
"Geometry": {
"BoundingBox": {
"Width": 1.0,
"Height": 1.0,
"Left": 0.0,
"Top": 0.0
},
"Polygon": [
{
"X": 8.657708380598926e-17,
"Y": 0.0
},
{
"X": 1.0,
"Y": 1.7308868137724391e-16
},
{
"X": 1.0,
"Y": 1.0
},
{
"X": 0.0,
"Y": 1.0
}
]
},
"Id": "7fb0313d-5dcb-4588-a4a0-1ff00644f828",
"Relationships": [
{
"Type": "CHILD",
"Ids": [
"8941f40a-46ce-4782-89db-a48ec20e1155",
"5fe08d00-a3da-4896-95ac-01f14b916047",
"d50c4852-5cc1-40da-adeb-f65a43bbb00e",
"d85ca7d4-3c4a-4b1c-9a56-d0d8e78c841a",
"4d710c4a-45c2-40fd-98b6-bd9ba5691916",
"aff271ae-220d-4f00-b78b-c40a6d303fb6",
~~
BoundingBoxが取れているのは分かるが肝心のテキストが見当たらない。
detect-document-text以外にもanalyze-documentというのがあるらしいので今度はこっちを指定して実行してみるぞい。コマンドの雰囲気から察するに表形式のデータを抽出出来るっぽい?
$ aws textract analyze-document \
--region us-east-1 \
--document '{"S3Object":{"Bucket":"amazon-textract-sample","Name":"estimate.png"}}' \
--feature-types '["TABLES","FORMS"]'
{
"DocumentMetadata": {
"Pages": 1
},
"Blocks": [
{
"BlockType": "PAGE",
"Geometry": {
"BoundingBox": {
"Width": 1.0,
"Height": 1.0,
"Left": 0.0,
"Top": 0.0
},
"Polygon": [
{
"X": 8.657708380598926e-17,
"Y": 0.0
},
{
"X": 1.0,
"Y": 1.7308868137724391e-16
},
{
"X": 1.0,
"Y": 1.0
},
{
"X": 0.0,
"Y": 1.0
}
]
},
"Id": "7fb0313d-5dcb-4588-a4a0-1ff00644f828",
"Relationships": [
{
"Type": "CHILD",
"Ids": [
"8941f40a-46ce-4782-89db-a48ec20e1155",
"5fe08d00-a3da-4896-95ac-01f14b916047",
"d50c4852-5cc1-40da-adeb-f65a43bbb00e",
"d85ca7d4-3c4a-4b1c-9a56-d0d8e78c841a",
"4d710c4a-45c2-40fd-98b6-bd9ba5691916",
"aff271ae-220d-4f00-b78b-c40a6d303fb6",
"2123aac0-a6ae-4bdc-941b-768c36ed4a23",
"0f9109e9-b859-4efc-a33a-39abcc673401",
"4b1a8446-9855-4524-9b00-2f788da54814",
"54146a4c-e80a-4ab8-a590-2e335a9be3f8",
"03b207f4-0c49-4027-a482-12141bca187c",
"0ddf7caa-fe4b-41ed-afb0-5cd182b9bf60",
"a7ec108f-84ff-44b4-8098-593d142f5fa9",
"05d884c4-befa-4ebc-9f37-4bb8585042b3",
"fa19d636-d6f0-42b6-aff8-634a6050e03e",
"ddc7a54f-0a69-4792-aec5-0ba1938f018d",
"1de2f209-e7ad-4a77-aa31-192cff3b9f3b",
"7e8d9536-fe69-4e6e-a614-5e10f7681369",
"9aba9e2c-3fe4-4174-94bb-0e84bd50b60c",
これまた同様にテキストが見当たらない。
デモ画面
レスポンスのjsonがでかすぎてどのようにデータが取得出来ているかイマイチわからんので、デモ画面で確かめてみる。
最初からこっちやっておけばよかった。
https://console.aws.amazon.com/textract/home?region=us-east-1#/demo
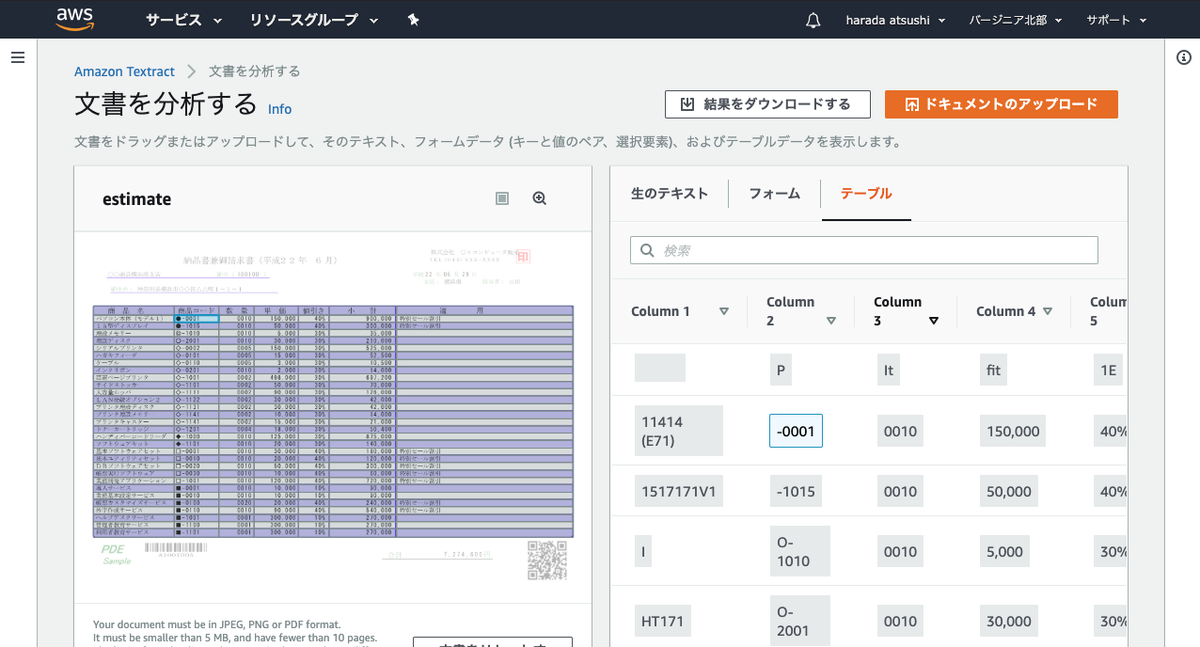
日本語以外のデータは取れている。これは日本語対応していないのでは。。
下記エントリによると対応していないらしい。先に言ってくれや。
日本語のドキュメントOCRに使いたかったのでざんぬん。